
What is a zkEVM?
Written by Alchemy
A zero-knowledge Ethereum Virtual Machine (zkEVM) is a virtual machine that generates zero-knowledge proofs to verify the correctness of programs. ZkEVMs are designed to execute smart contracts in a manner that supports zero-knowledge technology.
ZkEVMs are part of zero-knowledge (ZK) rollups, Ethereum layer 2 scaling solutions that improve throughput by transferring computation and state storage off-chain. A ZK-rollup submits transaction data to Ethereum along with zero-knowledge proofs verifying the validity of off-chain transaction batches.
Early ZK-rollups lacked the ability to execute smart contracts and were constrained to simple token swaps and payments. But, with the introduction of EVM-compatible zero-knowledge virtual machines, ZK-rollups are starting to support Ethereum dApps.
In this article, we explore how a zkEVM works, why it matters, and what types of zkEVM exist.
What is a zkEVM?
A zkEVM is an EVM-compatible virtual machine that supports zero-knowledge proof computation. Unlike regular virtual machines, a zkEVM proves the correctness of program execution, including the validity of inputs and outputs used in the operation.
We’ll break down this definition further to make it easier to understand:
EVM compatibility
The EVM (Ethereum Virtual Machine) is the runtime environment in which smart contracts deployed on the Ethereum network are executed. The EVM functions as a “world computer” that powers decentralized applications (dApps) running on the Ethereum blockchain.
A virtual machine is “EVM-compatible” if it can run programs created to run in the EVM environment. Such VMs can execute smart contracts written in Solidity or other high-level languages used in Ethereum development. ZkEVMs are EVM-compatible because they can execute Ethereum smart contracts without extensive modifications of the underlying logic
Support for zero-knowledge technology
The EVM was never designed to support zero-knowledge proofs, which makes building EVM-compatible, zero-knowledge-friendly virtual machines difficult. However, advances in research have made it possible—to some extent—to wrap EVM computation in zero-knowledge proofs.
Different zkEVM projects adopt different approaches to combining EVM execution with zero-knowledge proof computation. Each method has unique tradeoffs, which we explore in a later section of this guide.
How does a zkEVM work?
Like the EVM, a zkEVM is a virtual machine that transitions between states as a result of program operations. But the zkEVM goes further by producing a proof to attest to the correctness of every part of the computation. Essentially, a zkEVM uses a mechanism to prove that the execution steps (described earlier) followed rules.
To understand how a zkEVM works (and why it’s different), let's review how the EVM works currently.
How the EVM works
The Ethereum Virtual Machine is a state machine that moves from an old state to a new state in response to some inputs. Every smart contract execution triggers a change in the EVM’s state (called a “state transition”). Here’s a high-level overview of what happens during a smart contract transaction:
-
Contract bytecode (compiled from the source code) is loaded from the EVM’s storage and executed by peer-to-peer nodes on the EVM. Nodes use the same transaction inputs, which guarantees that each node arrives at the same result (or else they cannot reach consensus).
-
EVM Opcodes (contained in the bytecode) interact with different parts of the EVM’s state (memory, storage, and stack). Opcodes perform read-write operations—reading (getting) values from state storage and writing (sending) new values to the EVM’s storage.
-
EVM opcodes perform computation on the values obtained from state storage before returning the new values. This update results in the EVM transitioning to a new state (transactions are called “state transitions” for this reason). This new state is replicated by other nodes and remains until another transaction is executed.

How the zkEVM works
The zkEVM generates zero-knowledge proofs to verify various elements in each computation:
-
Bytecode access: Was the appropriate program code loaded correctly, from the right address?
-
Read-write operations: a. Did the program fetch the right values from stack/memory/storage before the computation? b. Did the program write the correct output values to the stack/memory/storage after completing execution?
-
Computation: Were the opcodes executed correctly (i.e., one after the other, without skipping steps)?
The architecture of a zkEVM
The zkEVM is divided into three parts: an execution environment, proving circuit, and verifier contract. Each component contributes to the zkEVM’s program execution, proof generation, and proof verification.
1. The execution environment
As the name suggests, the execution environment is where programs (smart contracts) are run in the zkEVM. The zkEVM’s execution environment functions much like the EVM: it takes the initial state and current transaction to output a new (final) state.
2. The proving circuit
The proving circuit produces zero-knowledge proofs verifying the validity of transactions computed in the execution environment. The proof generation process is completed using the pre-state, transaction inputs, and post-state information as inputs. After that, the prover obtains a succinct proof of the validity of that particular state transition.

3. The verifier contract
ZK-rollups submit validity proofs to a smart contract deployed on the L1 chain (Ethereum) for verification. The input (pre-states and transaction information) and output (final states) are also submitted to the verifier contract. Then the verifier runs computation on the provided proof and confirms that the submitted outputs were correctly computed from the inputs.
What are zkEVM opcodes?
ZkEVM opcodes are low-level machine instructions used for executing programs in an EVM-compatible ZK-rollup. As with the EVM, contracts written in high-level languages must be compiled to low-level language the VM can interpret (bytecode). This bytecode specifies the opcodes used in executing the program when it’s deployed in the VM.
We need zkEVM opcodes because regular EVM opcodes are inefficient for use in zero-knowledge proving circuits. There are generally two approaches to creating opcodes for zkEVMs:
- Building ZK circuits for native EVM opcodes
- Creating new languages for ZK proof computation
Build zero-knowledge circuits for native EVM opcodes
This approach requires implementing all EVM instruction sets in an arithmetic circuit—a complex and time-intensive task. The benefit is that developers can create smart contracts using existing blockchain developer tooling or port existing Ethereum contracts to ZK-rollups without extensive modifications.
Create new languages for ZK proof computation
This approach requires building a new language—designed to support validity proofs—and developing custom opcodes. Developers will need to either write contracts directly in the new language or compile Solidity source code to custom zkEVM opcodes.
While this method is often simpler to implement than the first approach, it has drawbacks. For instance, developers may be unable to access existing Ethereum infrastructure and resources.
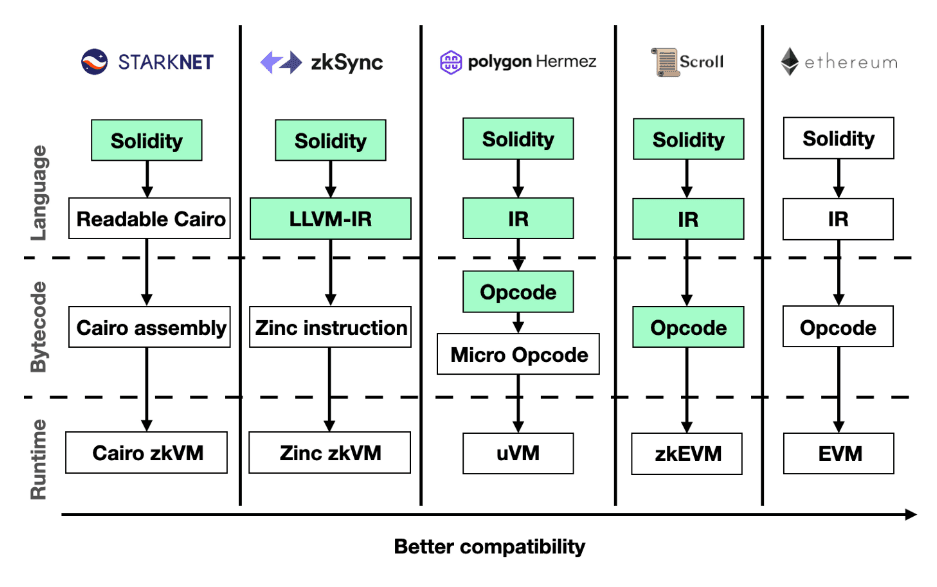
What makes building a zkEVM difficult?
Because the EVM wasn’t built with zk-proof computation in mind, it has features that are unfriendly for proving circuits. Here is a brief overview of four things that make building zkEVMs difficult:
- Special opcodes
- Stack-based architecture
- Storage overhead
- Proving costs
1. Special opcodes
Unlike a regular VM, the EVM uses special opcodes for program execution (CALL, DELEGATECALL) and error handling (REVERT, INVALID), amongst other operations. This adds complexity to the process of designing the proving circuit for EVM operations.
2. Stack-based architecture
The EVM uses a stack-based architecture which, although simpler than a register-based structure, increases the difficulty of proving computation. This is why prominent zero-knowledge VMs, such as ZkSync's zkEVM and StarkWare's StarkNet use a register-based model.
3. Storage overhead
The EVM's storage layout relies on Keccak hashing functions and a Merkle Patricia Trie, both of which have a high proving overhead. Some zkVMs, like ZkSync, attempt to sidestep this problem by replacing the KECCAK256 function—but this can break compatibility with existing Ethereum tooling and infrastructure.
4. Proving costs
Even if the aforementioned problems are solved, there's still the proof-generation process to contend with. Generating zero-knowledge proofs requires specialized hardware along with considerable investment in time, money, and effort.
Although not exhaustive, this list presents some of the problems that hamper efforts to build EVM-compatible zkEVMs. Nonetheless, several breakthroughs in zero-knowledge technology have made it possible to mitigate those problems—leading to renewed interest in zkEVM solutions.
Why is a zkEVM important?
Building a fully functional zkEVM will encourage the development of EVM-compatible ZK-rollup projects. This presents several advantages:
- Secure scalability
- Cheaper costs
- Faster finality and capital efficiency
- Network effects
1. Secure scalability
Per protocol rules, all validating nodes must re-execute all computations performed in the Ethereum Virtual Machine. This approach ensures security since Ethereum nodes can independently verify the correctness of programs, but it places limits on scalability the Ethereum network can manage just ~ 15-20 transactions).
EVM-compatible ZK-rollups can fix Ethereum’s throughput issues without undermining network security. Like other scaling protocols, ZK-rollups are not burdened by Ethereum’s consensus protocol rules and can optimize for execution speed. Some estimates suggest ZK-rollups can process ~ 2000 transactions per second without incurring Ethereum’s high fees.
However, ZK-rollups have higher security guarantees compared to other scaling projects; they verify correctness of off-chain computation with validity proofs. It means transactions performed by smart contracts on L2 can be reliably verified on L1 (Ethereum) without nodes having to re-execute the operations. This can significantly increase Ethereum’s processing speed without reducing security.
2. Cheaper costs
Rollups derive security from Ethereum Mainnet by writing transaction data to Ethereum as CALLDATA. However, optimistic rollups and ZK-rollups differ in how much data they must post on Ethereum.
Because optimistic rollups don’t provide proof of validity for off-chain transactions, they need to publish all transaction-related data on-chain (including signatures and transaction parameters). Without putting all data on-chain, challengers cannot construct fraud proofs used to dispute invalid rollup transactions.
Conversely, ZK-rollups can afford to post minimal data to Ethereum because validity proofs already guarantee the trustworthiness of state transitions. The zkEVM may even omit transaction inputs and publish only final state changes, further reducing CALLDATA requirements.
This is beneficial for developers and users because a large percentage of rollup costs come from posting data on-chain. By reducing CALLDATA to a minimum, ZK-rollups can make it cheaper to use dApps, like decentralized exchanges, NFT marketplaces, prediction markets, and many more.
3. Faster finality and capital efficiency
Besides better security, ZK-rollups have another advantage over optimistic rollups: faster finality. Finality in blockchains is the time it takes for a transaction to become irreversible; a transaction can only be finalized if network participants have objective proof of its validity.
With ZK-rollups, transactions executed in the zkEVM are often finalized immediately after they are posted on Ethereum. Since each transaction batch comes with an instantly verifiable proof of validity, the main Ethereum chain can quickly apply state updates.
Since optimistic rollups only post VM transactions without proofs, the challenge period must elapse before transactions achieve finality. The challenge period is a 1-2 week period during which anyone can challenge a transaction after it is submitted to Ethereum.
Slower finality has many implications for the user experience. For example, users cannot withdraw assets from the rollup until the delay period expires. Liquidity providers may solve the problem but may be ineffective if the withdrawal involves high-value assets or even NFTs.
A zkEVM has none of those problems described above. Faster finality is great for power users, such as NFT traders, DeFi investors, or arbitrage traders who need to move around assets seamlessly (especially between L1 and L2).
4. Network effects
The most important reason for building EVM-compatible zkVMs is to leverage Ethereum's network effects. As the world's biggest smart contracts platform, Ethereum has a large ecosystem that provides value to both developers and projects.
For instance, developers can access battle-tested and audited code libraries, extensive tooling, documentation, and so on. Creating a new zkVM that is incompatible with Ethereum's infrastructure would cut off projects and development teams from harnessing Ethereum's network effects.
What types of zkEVMs exist?
Current zkEVM projects fall into two main categories: zkVMs supporting native EVM opcodes and zkVMs using customized EVM opcodes. Below we compare different zkEVM protocols and explain how they work:
Polygon zkEVM
Polygon Hermez is a Polygon ZK-rollup with a zero-knowledge virtual machine designed to support EVM compatibility. To do this, EVM bytecode is compiled into "micro opcodes" and executed in the uVM—a virtual machine that uses SNARK and STARK proofs to verify the correctness of program execution.
The decision to combine the two proof types is strategic. STARK (Scalable Transparent ARgument of Knowledge) proofs are faster to generate, but SNARK (Succinct Non-Interactive Argument of Knowledge) proofs are smaller and cheaper to verify on Ethereum.
The Polygon Hermez zkEVM uses a STARK proving circuit to generate proofs of validity for state transitions. A STARK proof verifies the correctness of STARK proofs (think of it as generating "proof of a proof") and is submitted to Ethereum for verification.
zkSync zkEVM
zkSync is an EVM-compatible ZK-rollup developed by Matter Labs and powered by its own zkEVM. ZkSync achieves compatibility with Ethereum using the following strategy:
-
Compiling contract code written in Solidity to Yul, an intermediate language that can be compiled into bytecode for different virtual machines.
-
Re-compiling the Yul bytecode (using the LLVM framework) to a custom, circuit-compatible bytecode set specially designed for zkSync's zkEVM.
Like Polygon Hermez, the zkSync zkEVM achieves EVM compatibility at the language level, not the bytecode level. For example, traditional multiplication and addition opcodes (ADDMOD, SMOD, MULMOD) are not supported by zkSync's zkEVM.
Scroll zkEVM
Scroll is a new zero-knowledge EVM implementation under development. The Scroll team plans to design zero-knowledge circuits for each EVM opcode. This would allow developers to deploy Ethereum-native smart contracts EVM on Scroll without needing to modify the underlying EVM bytecode.
Among other things, the Scroll zkEVM will use a "cryptographic accumulator" to verify the correctness of storage. This is used to prove that the contract bytecode was loaded correctly from the given address.
It also provides a circuit for linking the bytecode with the execution trace. The execution trace is a sequence specifying what VM instructions were executed and in what order. Provers will submit the execution trace during proof generation to verify that the computation was consistent with the original bytecode.
AppliedZKP zkEVM
Applied ZKP is a project funded by the Ethereum Foundation to develop an EVM-compatible ZK-rollup and a mechanism for generating validity proofs for Ethereum blocks. The last part is critical because pairing blocks with validity proofs would remove the need for nodes to re-execute blocks.
Applied ZKP's innovation is the separation of computation from storage. It uses two types of validity proofs—state proofs and EVM proofs:
State proofs
Checks that operations touching storage, memory, and stack happened correctly. State proofs essentially verify the accuracy of read-write operations.
EVM proofs
Checks that the computation called the accurate opcode at the right time. The EVM proofs verify the computation itself and also confirms that the state proof executed the right operation for each opcode.
The AppliedZKP zkEVM uses a bus mapping to link the state proof and EVM proof. Also, both proofs must be verified before the Ethereum block is deemed valid.
Where are we in the development progress of zkEVMs?
Except for zkSync, most zero-knowledge EVMs are still under production. Nevertheless, growing development in zero-knowledge technology means the prospect of a fully functional zkEVMs is better than ever.
In the meantime developers can leverage the benefits of zero-knowledge applications with the StarkNet zero-knowledge VM. StarkNet is not EVM-compatible, but can compile Solidity source code to custom ZK-friendly bytecode. You can also choose to write contracts in Cairo (StarkNet's language).
Sign up with Alchemy for free to start building on StarkNet today.
Frequently asked questions
What does zkEVM stand for?
zkEVM stands for Zero-Knowledge Ethereum Virtual Machine, a virtual machine that executes smart contracts while generating zero-knowledge proofs to verify correctness.
How does a zkEVM differ from the standard Ethereum virtual machine?
A zkEVM is EVM-compatible but generates zero-knowledge proofs to verify transaction validity, enabling off-chain execution with on-chain verification for improved scalability.
What are the main components of a zkEVM?
A zkEVM consists of three parts: an execution environment where smart contracts run, a proving circuit that generates zero-knowledge proofs, and a verifier contract that checks proofs on Ethereum Layer 1.
What are zkEVMs used for?
zkEVMs power ZK-rollups, which are Ethereum Layer 2 scaling solutions that batch transactions off-chain and submit validity proofs to Layer 1 for faster, cheaper execution.
Why are zkEVMs difficult to build?
Building zkEVMs is challenging because the EVM wasn't designed for zero-knowledge proofs, featuring special opcodes, stack-based architecture, storage overhead, and high proving costs that complicate circuit design.
How do zkEVMs improve scalability compared to optimistic rollups?
zkEVMs provide immediate finality through validity proofs, eliminating the 1-2 week challenge period required by optimistic rollups and enabling faster transaction processing.
What are zkEVM opcodes?
zkEVM opcodes are low-level machine instructions for executing programs in ZK-rollups, created either by building ZK circuits for native EVM opcodes or developing new ZK-friendly languages.
What are some examples of zkEVM implementations?
Examples include Polygon zkEVM (using micro opcodes and SNARK/STARK proofs), zkSync (compiling Solidity to custom bytecode), and Scroll (designing circuits for each EVM opcode).
Related Overviews




Build blockchain magic
Alchemy combines the most powerful web3 developer products and tools with resources, community and legendary support.